Data Guide
To run ForeTiS on your data, you need to provide a CSV or HDF5/H5/H5PY file like described below. ForeTiS is designed to work with several file types besides the one we provide in this repository as tutorial data. For a better understanding, we provide a tutorial video, where we conduct case studies and in this course also go into detail about the data to be provided: tut_adv_casestudies.
CSV
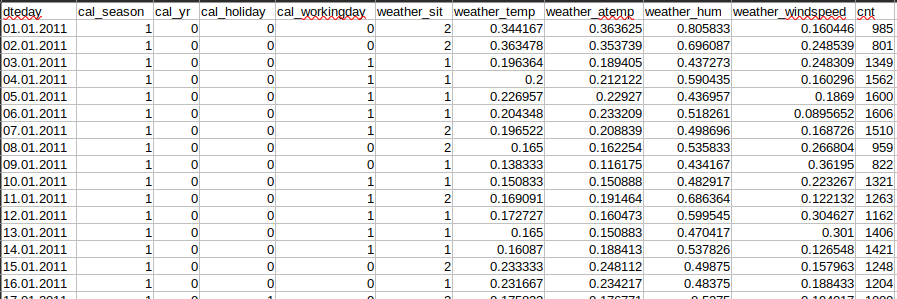
To use your own CSV data, the dataset must be in such a manner that the dataset_specific_config.ini file can be filled like you can see in the figure below or as described under dataset_specific_config.ini. This figure is an example for a csv file that is suitable for ForeTiS. Important is that it contains a header with the naming of the columns, one sample per row, features and target value in the columns, and a column with the time information.
dataset_specific_config.ini
In this file you can define some characteristics of your data. The following points should be adjusted:
values_for_counter: the values that should trigger the counter adder
columns_for_counter: the columns where the counter adder should be applied
columns_for_lags: the columns that should be lagged by one sample
columns_for_rolling_mean: the columns where the rolling mean should be applied
columns_for_lags_rolling_mean: the columns where seasonal lagged rolling mean should be applied
imputation: whether to perfrom imputation or not
resample_weekly: whether to resample weekly or not
string_columns: columns containing strings
float_columns: columns containing floats
time_column: columns containing the time information
time_format: the time format, either “W”, “D”, or “H”
seasonal_periods: how many datapoints one season has
featuresets_regex: regular expression with which the feature sets should be filtered
features: the features of the dataset
categorical_columns: the categorical columns of the dataset
max_seasonal_lags: maximal number of seasonal lags to be applied
target_column: the target column for the prediction
In the Video tutorial: ForeTiS case studies, you can see exemplary on two case studies, how the configuration file should look like.
Preprocessing
In the preprocessing step, the actions defined in the dataset_specific_config.ini file will be performed. Additionally, useless columns get dropped and, if the amount of a focus product gets predicted, the correlating products gets calculated. Afterwards, in the featureadding and resampling step, the feature engineering happens where additional useful statisical and calendar features (like defined in the dataset_specific_config.ini file) get added and the categorical features get on hot encoded. Then, if defined, the data gets resampled and the datasets like described in HDF5 / H5 / H5PY will be created and saved. Once the dataset is preprocessed and the HDF5 file is generated, the algorithm recognized this when restarting experiments and directly reads in the HDF5 file to avoid redoing the time consuming preprocessing step.